
SEO: How to Deal With Duplicate Content

Why is duplicate content a problem, and how can you solve it? In the following article, we'll answer these questions.
 If you already have specific suspicions, a simple Google search does the trick. Copy one or two sentences from the content, bracket the text and enter it into the Google search bar. As a result, you'll find all pages where this exact wording was used. Of course, you are also able to search for titles or other content components using the same method, and even use image search to search for specific images.
Now you can contact the page operator and demand that he removes the content. You can also turn to Google this way for different legal issues. Google provides this form for reports on copyright infringement (DMCA).
If you already have specific suspicions, a simple Google search does the trick. Copy one or two sentences from the content, bracket the text and enter it into the Google search bar. As a result, you'll find all pages where this exact wording was used. Of course, you are also able to search for titles or other content components using the same method, and even use image search to search for specific images.
Now you can contact the page operator and demand that he removes the content. You can also turn to Google this way for different legal issues. Google provides this form for reports on copyright infringement (DMCA).
Duplicate Content: the Problem
Now you might say you didn't have duplicate content. But most likely, the reason for that is that you don't fully know what duplicate content is. You made sure that the contents of your website don't appear in several places at once? Sounds good. You make sure that your content is not used by third parties, allowing you to assure that your content is only available on your site? Sounds good as well. Unfortunately, this only covers the secondary problems. Most cases of duplicate content have technological origins. Let's stick to the problem that duplicate content is created when other page operators use your content, for content partnerships, for instance. The negative consequences of this duplicate content can already be avoided by placing a link at the respective content that leads back to your original. Expediently, add something like "The original article was released on YourWebsite", and the search engine has enough hints to find the origin of the content.The Search Engine and You: Sharing One Interest
In the end, duplicate content is not only a problem for you, but also for the search engine. The value of a search engine is defined by its result. The user wants to find relevant content on his search keyword. The search engine is confused by duplicate content and is not really able to tell which one of the five identical texts is the original. However, you depend on the search engine as well, allowing users to find you, which is why Google and co can easily turn their problem into yours. In fact, it actually is your problem when Google guides your visitor to the fifth copy of your original, instead of leading them to you, the originator of the content. Let's just say that there's an interest congruence. Search engines want to find relevant originals, and you want search engines to display your relevant originals.The Consequences of Duplicate Content: Until Someone Cries
Regarding the consequences of duplicate content, opinions differ, although Google takes on a rather clear stance. There are no penalties for duplicate content. Negative consequences, with a bad ranking above all else, basically come up by themselves. If the original content can't be identified without any doubts, you'll run the risk of having to share the attention with your copies. Based on its algorithm, Google will then choose one version that will pass all others, even though it might not be the original.Intentional Duplicate Content on Own or External Pages
First, let's take care of the case of you intentionally having the same content on your page in multiple places. Now, the search engines index all versions, immediately creating the issue of relevance selection. However, the option to distribute external links to all versions is even worse, as this weakens the individual content under SEO aspects. It would be a lot more effective to have a pooled link placement to one content. Here's where you use the concept of the "canonical URL". This canonical URL is the content you define as the original. Now, enter this original URL as the canonical URL in the header of the pages that contain copies. This works as follows:<link rel="canonical" href="http://www.example.com/product.php?item=swedish-fish" />
(The Example is From the Google Webmaster Central Blog)
The search engine recognizes this hint as some kind of redirect to the original content. This form of redirection is a soft variant of the 301 placed via Htaccess as a permanent redirect, which would not help us in this situation.
So much for internal duplicate content. If you don't have access to the header of the page where the content is displayed, you can go back to the above-mentioned tip and manually add the link to the original URL at the end or beginning of the duplicate content. I'd always place the link with a description, even if you have access to the page header because the user won't really have access to the canonical link in the header.
Unintended Duplicate Content on External Sites
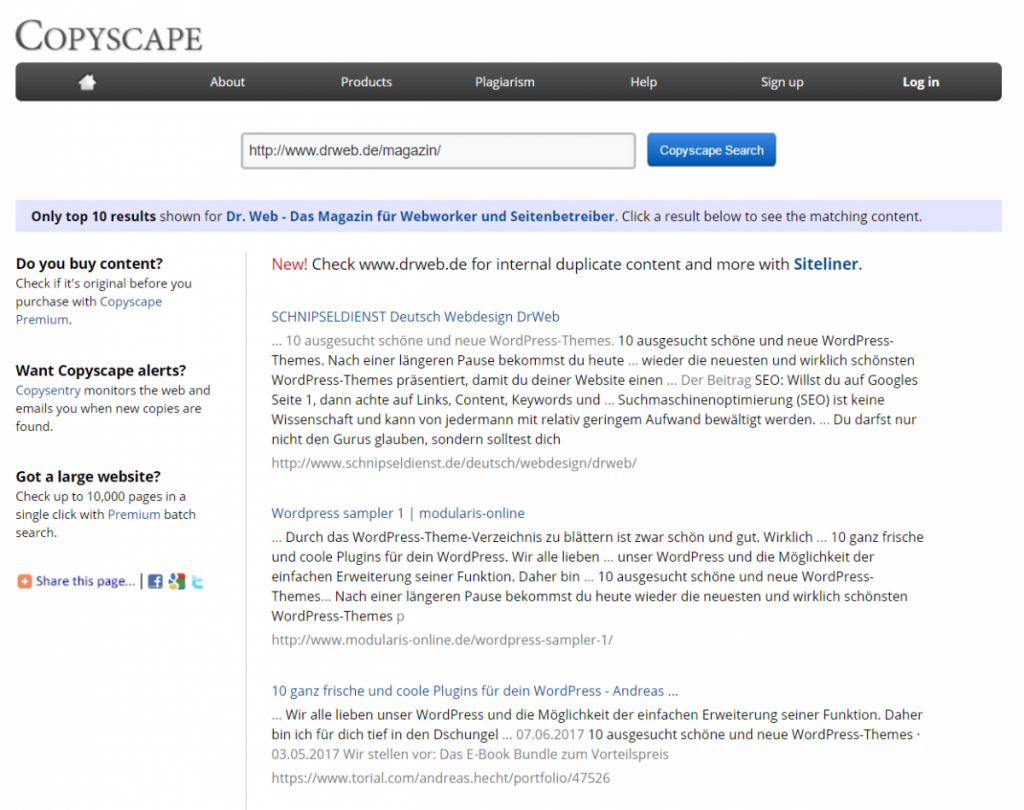
Of course, the options of using a 301, a canonical link, or even a regular link in the text don't work for unauthorized usage of your content somewhere on the internet. At most, the latter could work by making sure that your RSS feed contains the backlink to the original on your page at the end of every article. So-called scraper sites that generate their content by sweeping through stranger's RSS feeds may take your content the way it is in your RSS feed, leaving the chance for your backlink to remain. The professional scraper automatically removes these links, but it's worth a try, as the extra effort only comes up once during the configuration of the feed. The first issue is finding the external duplicate content in the first place. Here, special search engines like Copyscape come into play. There, all you need to do is enter your URL. The service then searches the web for content that's identical to your website. This is what the search result for Dr. Web looks like, for example:
If you already have specific suspicions, a simple Google search does the trick. Copy one or two sentences from the content, bracket the text and enter it into the Google search bar. As a result, you'll find all pages where this exact wording was used. Of course, you are also able to search for titles or other content components using the same method, and even use image search to search for specific images.
Now you can contact the page operator and demand that he removes the content. You can also turn to Google this way for different legal issues. Google provides this form for reports on copyright infringement (DMCA).
Unintended Duplicate Content on Your Own Pages
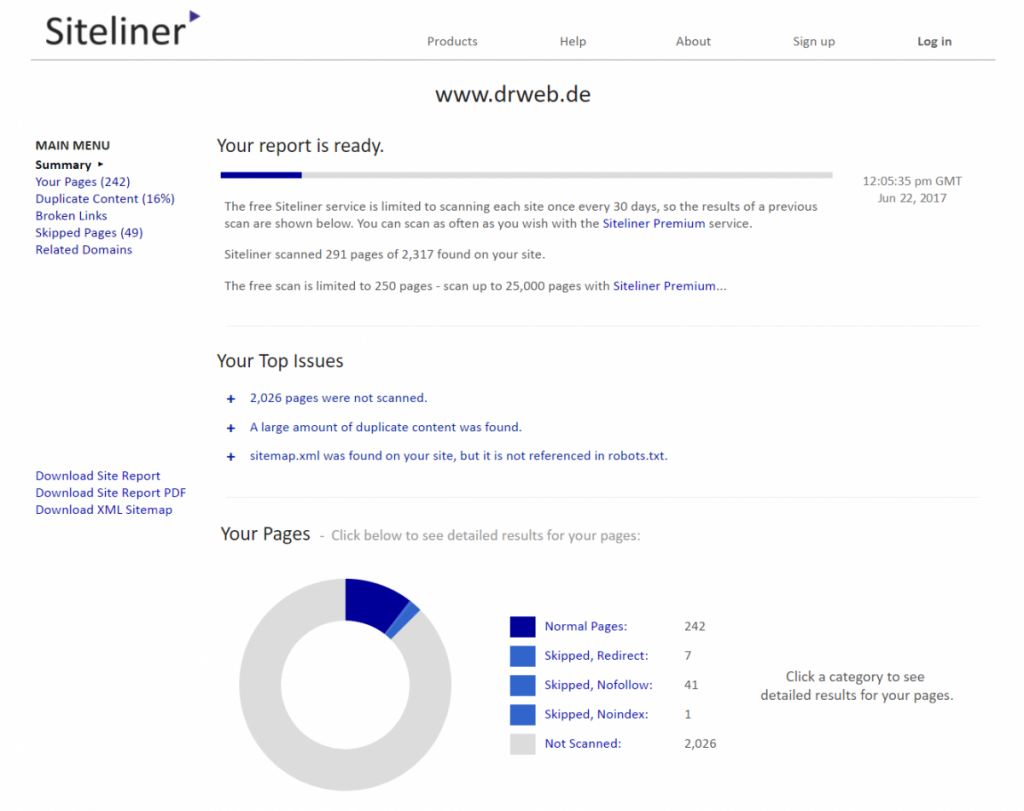
Duplicate content on your own pages is a much greater problem. You might not believe it, but that's how it is. Of course, that's not your intention, and you don't intentionally support this. The reason for duplicate content on your website is almost 100 percent sure to be a technological one. Modern content management systems offer the flexibility to make your content accessible under a plethora of different URLs. Let's use WordPress as an example. Here, you could access the same article via the post URL, a URL that includes the author, as well as a URL that contains the content. Furthermore, you could use a URL with different parameters, for pagination, sorting, or tracking, which also leads to the same content. This way, you would have created some great duplicate content without being aware of that. Another popular source for duplicate content is print-friendly websites that are still very commonly used instead of a print stylesheet. In many cases, these adjusted pages appear to be especially relevant, as they only provide pure content, without the disruptive surroundings. That's not the intention... Pages that are accessible with and without www, as well as via HTTPS or simple HTTP, or with or without an ending slash are just as problematic. All of them create duplicate content. The Google Webmaster Tools offer an introduction to the search for duplicate content on your own website. Here, open "Display in search", and then "HTML improvements". If there are pages with duplicates in the title or description, you'll find them listed here. A result in this list would speak for the existence of duplicate content that could be found easily. The tool Siteliner works like Copyscape, but for your own contents. Here, you receive meticulously researched evaluations that seem more dramatic than they actually are on first sight. The reason for that is that every single duplicate will be found and made visible. Most of the displayed duplicates will be intentional ones, though, like the author boxes under the articles.
Structural Avoidance of Duplicate Content
Most duplicates can be taken care of using simple means, as they are no doublets in the literal sense. In fact, they are contents that are accessible in multiple ways. Thus, the keyword here is: URL hygiene. First, let's make sure that, when using HTTPS, the respective protocol is always used, and that there are no more deliveries via HTTP. Using Mod_rewrite and htacces, this is done like this:RewriteEngine On
RewriteCond %{HTTPS} !=on
RewriteRule ^/?(.*) https://www.drweb.de/$1 [R=301,L]
In order to assure that the www is always added to the URL, avoiding duplicates due to a missing protocol specification, write:
RewriteEngine On
RewriteCond %{HTTP_HOST} ^drweb.de$
RewriteRule (.*) http://www.drweb.de$1 [R=301]
Now, let's take care of the ending slash at the end of URLs. This is a problem that a lot of you won't have, but it is easy to prevent. So why not do it? This htaccess causes every URL to receive the ending slash:
RewriteEngine On
%{REQUEST_FILENAME} !-f
RewriteRule ^([^/]+)/?$ https://www.drweb.de/$1/ [R=301,L]
You remain free to go the reversed way, in order to always avoid the slash. The same applies to forcing the www. It's just important to keep the consistency throughout your entire website.
In most cases, superfluous URLs that different content management systems provide as additional ways to the content can simply be turned off in the respective CMS' settings. That's the best way top avoid these potential duplicates.
If that doesn't work, there's the last resort option of using noindex in the meta tags of the respective page or the complete exclusion of single structure areas from the Google index via the robots.txt. This way of completely blocking content is not recommended by Google, however. If unnecessary URL variants can't be turned off by the system, you should use the canonical tag in order to point to the URL that you want to display the content's original URL.
Conclusion: Pretty Much Every Website Operator Has Problems With Duplicate Content
Usually, the question won't be whether you have a problem with duplicate content, but rather to what extent. Fortunately, all presented ways to avoid duplicates on your own pages can be put into practice quite easily. You just need to invest the effort.Further Reading:
- Duplicate Content: Causes and Solutions | Joost de Valk, Yoast SEO
- Duplicate Content SEO Advice From Google | Shaun Anderson, Hobo SEO Services
- SEO: How to Detect, Correct Duplicate Content Pages | Hamlet Battista, Practical Ecommerce
Thanks for sharing this amazing informative seo article. i like this . i will follow your instruction.